Pandas 누락값 처리 - Handling Missing Values IN Python
누락 값 처리하는 4가지 스킬
누락을 발견하고, 누락 규모 파악하고, 누락값을 채우거나 버리는 작업이 필요하다.
Discovering missing values : isnull(), notnull()
Counting missing values : isnull().sum()
Filling in for missing values : fillna(), interpolate()
Filtering out missing values : dropna()
How to Identify and Drop Null Values | Handling Missing Values in Python
이 영상은 누락 값을 파악하고, 필터링하는 방법을 서술한 영상이다.
인도분이라 발음이 조금 힘들 수는 있지만 듣다보면 익숙해질 정도이고, 설명 자체는 너무 명확한 강의였다 :D
https://www.youtube.com/watch?v=57vFbsiZYHg
1. 데이터에 Null 이 어떻게 있는지 확인하자.
import pandas as pd
orders = pd.read_excel('C:/Users/alicia/Desktop/Sample - Superstore Sales.xls', 0)
orders.isnull().sum()
orders[orders['Product Base Margin'].isnull()]
orders DataFrame 의 각 셀 (한 개의 값, 행/열 intersection) 단위로 null 여부 true/false 값을 확인하고,
sum 하면 true 1 / false 0 기준으로 모든 행에 대해서 값을 더한다.
sum 결과가 0 이면 누락된 데이터가 없는 것 / 0이 아니면 누락 데이터가 있는 것이다.
위 데이터에서는 'Product Base Margin' 열에서 Null 이 발견되었다. 특정 열이 Null value 가 있다면 이렇게 확인해보자.
2. Null Value 가 있는 행을 날려버리자!
orders.shape
orders.dropna(how='any').shape
orders.dropna(how='all').shape
orders.dropna(subset=['Customer Name', 'Province'], how='all').shape
orders.dropna(how='any', thresh=1).shape
- how: any 행 내에 어떤 값이라도 / all 행 내 모든 값이 null 일 경우 행을 날리자.
- subset/how: subset 특정 칼럼 기준으로 any 행내 어떤 값이라도 / all 행 네 모든 값에 대해 null 일 경우 행을 날리자.
- thresh/how: 전체 컬럼값 중 1개 이상의 행에 대해 null 일 경우 행을 날리자.
참고. 영상 중에 요렇게 dropna() 메소드를 찍어놓고, 사용가능한 옵션들을 살펴보는 습관을 들이자 :)
How to Fill Up NA Values | Various ways to fill missing values in python
동일한 분의 누락값에 대해 적당한 값으로 채워넣는 영상!
https://www.youtube.com/watch?v=ktQOTU7hxCo
null_values = pd.Series([1, np.NaN, 2, np.NaN, 3,4, np.NaN, np.NaN, 8])
null_values.fillna(method='ffill')
null_values.fillna(method='ffill', limit=1)
null_values.fillna(0)
null_values.fillna(np.mean(null_values))
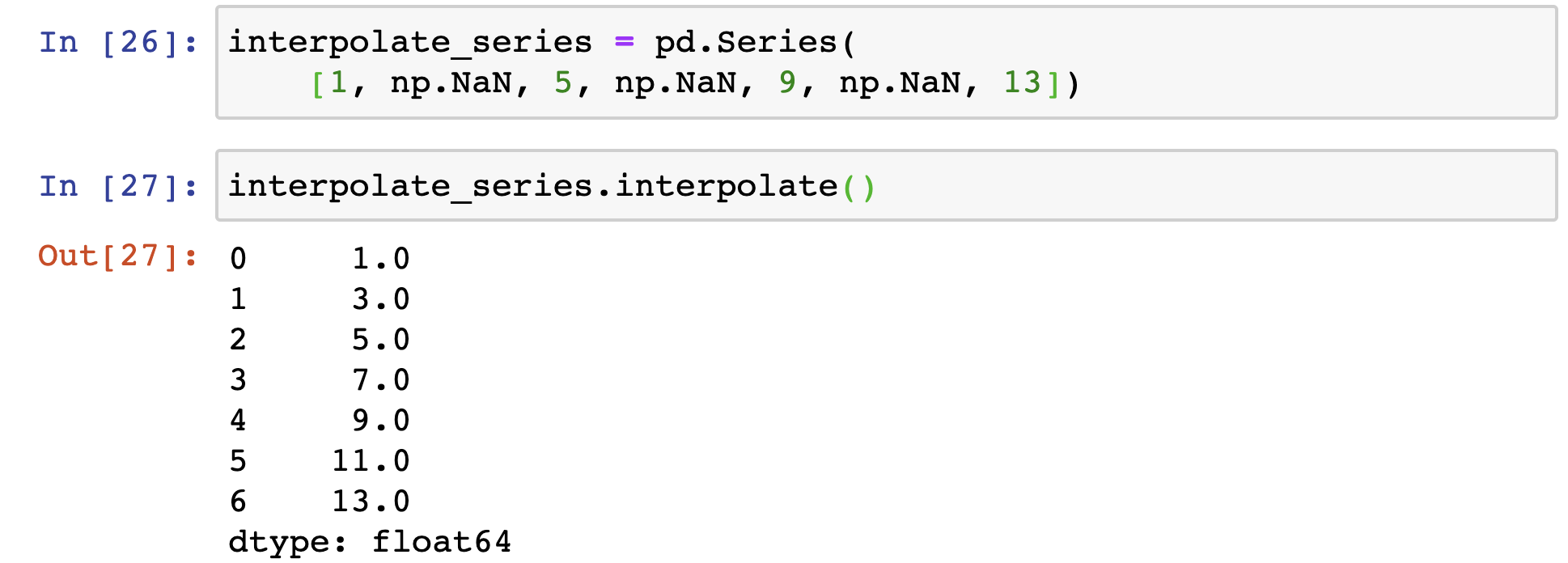
null_values.interpolate()
Q. interpolate? statistical term!
how the values are distributed based on trend and interval
요렇게 NaN 을 중간 값으로 채울수 있다. :ㅇ