-
[SQL] data.world tutorial SQL GROUP BY 예제 풀이데이터 분석/DB & SQL 2020. 5. 1. 11:53
GROUP BY
쿼리 니즈에서 Aggregation 과 함께 많이 쓰이는 Group By clauseshttps://docs.data.world/documentation/sql/concepts/intermediate/GROUP_BY.html
GROUP BY and FILTER
Learn about GROUP BY and FILTER in this SQL tutorial. Visit for a full course on learning the basics of SQL.
docs.data.world
GROUP BY 의 원리 1줄 정리
GROUP BY enables you to use aggregate functions on groups of data returned from a query.
GROUP BY 를 통해 데이터 그룹 단위로 집계함 수를 사용할 수 있다. 즉 엑셀의 피벗테이블 pivot_table 과 같은 기능이다.
1. 요구사항을 검토한다.
If we wanted to know the average value of the deals won by each sales person from highest average to lowest
the average value of deals aggregated by manager- 성사된 거래 의 평균 가치인데
- 각 sales person 단위로 위 값을 알고싶다. --> 결과 데이터셋 a
- 그리고 매니저 기준으로도 알고 싶다. --> 결과 데이터셋 b
- 물론 highest 에서 lowest 순서로 정렬한다.2. Dataset 을 확인한다.
쿼리하기에 앞서 deal_stage 에 따라 close_vlaue 가 어떻게 쌓이는지 확인한다.

deal_stage 에 따른 close_value 3. 집계 추출
a. the average deal won
데이터 그룹 단위가 없으므로 sales_pipeline 내의 모든 성사된 거래를 대상으로 평균값을 추출한다.
SELECT AVG(close_value) FROM sales_pipeline
WHERE deal_stage = "Won"b. the average value of the deals won by each sales person
데이터 그룹 단위가 sales_person 이다. sales_pipeline 내의 모든 성사된 거래를 각 sales_person 단위로 평균값을 추출한다.
SELECT sales_agent, AVG(close_value)
FROM sales_pipeline
WHERE deal_stage = "Won"
GROUP BY sales_agentc. average value of deals aggregated by manager
데이터 그룹 단위가 manager 이다. sales_pipeline 내의 모든 성사된 거래를 각 manager 단위로 평균값을 추출한다.
이 때, sales_agent 와 manager 정보는 sales_teams 에 있다.
sales_teams 를 살펴본 결과 sales_agent 들은 manager 를 가지고 있다.
manager 기준을 참고하기 위해서 거래 정보에 sales_agent 를 기준으로 manager 정보를 추가한 후 집계해야한다.SELECT team.manager, AVG(pipeline.close_value)
FROM sales_pipeline AS pipeline
LEFT OUTER JOIN sales_teams AS team ON pipeline.sales_agent = team.sales_agent
WHERE pipeline.deal_stage = "Won"
GROUP BY manager4. 추출 대상 컬럼을 지정하고 정렬한다. + 5. 컬럼명과 데이터타입을 확인한다.
필드명을 정리하고 새롭게 정의된 평균 기준으로 내림차순 정렬한다.
가독성을 위해 줄바꿈을 해주었다.
- 결과 데이터셋 컬럼명을 명시하는 SELECT 문
- 데이터 조회대상인 FROM/WHERE
- 그리고 결과 데이터셋의 조건 및 기타 등등을 지정하는 GROUP BY, ORDER BYb. the average value of the deals won by each sales person
SELECT sales_agent, AVG(close_value) AS average_deal_value
FROM sales_pipeline
WHERE deal_stage = "Won"
GROUP BY sales_agent
ORDER BY average_deal_value DESC결과 데이터셋: sales_agent 단위 평균 거래단가 (총 30명)
c. average value of deals aggregated by manager
SELECT team.manager AS manager,
AVG(pipeline.close_value) AS average_deal_valueFROM sales_pipeline AS pipeline
LEFT OUTER JOIN sales_teams AS team ON pipeline.sales_agent = team.sales_agent
WHERE pipeline.deal_stage = "Won"
GROUP BY manager
ORDER BY average_deal_value DESC결과 데이터셋: manager 단위 평균 거래단가 (총 6명)
주의사항
주의. GROUP BY 문을 포함할 경우 SELECT 쿼리 대상은 집계기준 (데이터그룹) 이거나 집계결과 (집계함수를 통한) 여야만 한다.
만약 다른 컬럼이 비집고 들어갈 경우 이런 문제점이 생긴다.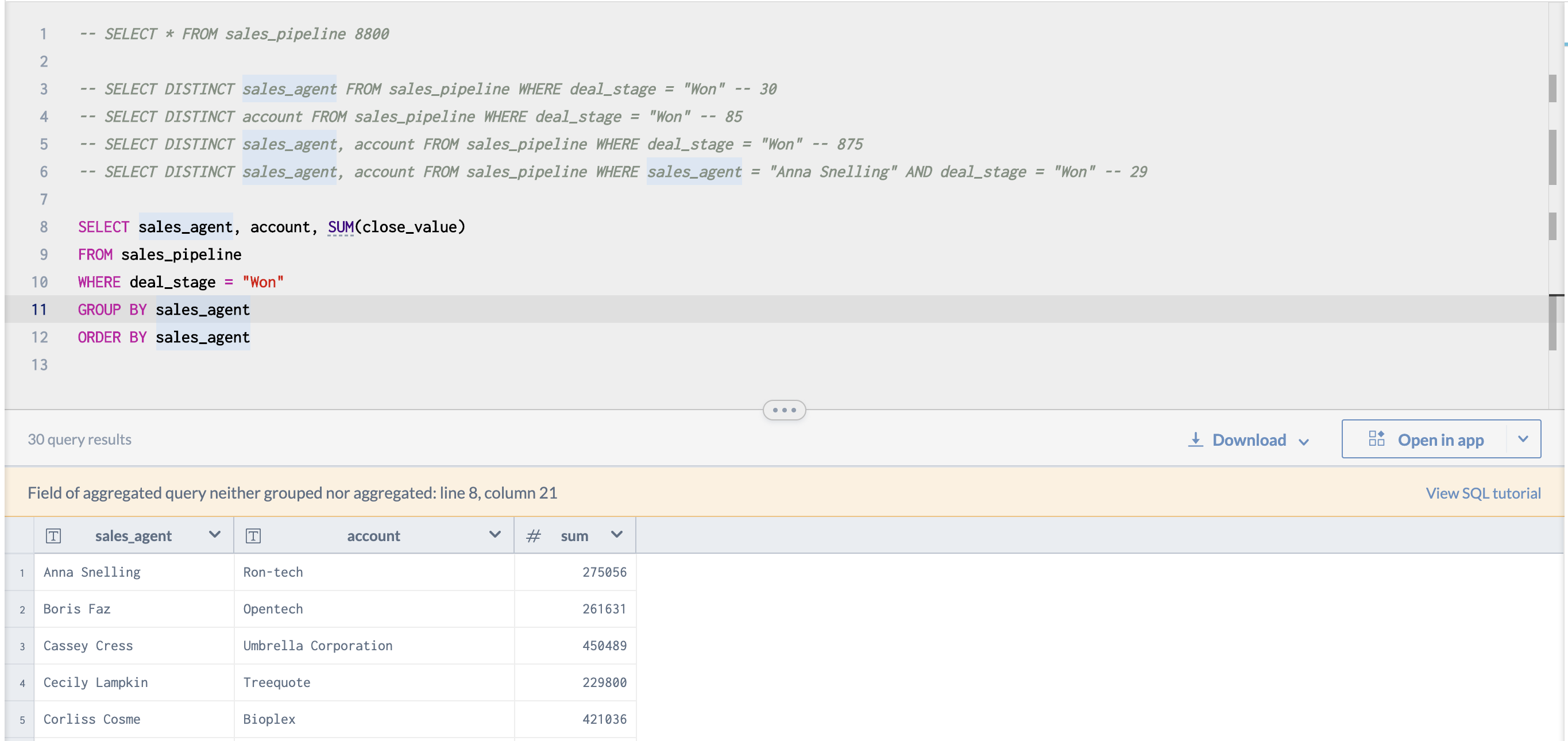
집계기준 sales_agent, 집계결과 SUM(close_value) 가 아닌 생뚱맞은 account 성사된 거래의 sales_agent 는 30명
성사된 거래의 account 는 86개
성사된 거래의 sales_agent X account 조합 은 875 개 이다.GROUP BY 기준이 아닌 account 가 들어가도 결과는 sales_agent 기준 30개 이다.
GROUP BY 기준 sales_agent 기준으로 account 아무값 하나만 가져온 것을 확인할 수 있다.
쿼리 문법상 틀린 것은 아니지만, 기대한 결과가 아닐 확률이 높다.
관련하여 쿼리실행창은 주황 알럿판넬을 띄운다. Field of aggregated query neither grouped nor aggregated만약 sales_agent 와 account 기준으로 거래단가를 알고 싶다면 GROUP BY 기준에 account 를 추가해주면 된다.

엑셀의 피벗테이블을 SQL 로 추출하는 방법을 알아보았다.
'데이터 분석 > DB & SQL' 카테고리의 다른 글
[SQL] data.world tutorial SQL UNION 예제 풀이 (0) 2020.05.01 [SQL] data.world tutorial SQL GROUP BY FILTER, HAVING 예제 풀이 (0) 2020.05.01 [SQL] data.world tutorial SQL Aggregatio 예제 풀이 (0) 2020.05.01 [SQL] data.world tutorial SQL SELF JOIN 예제 풀이 (0) 2020.05.01 [SQL] data.world tutorial SQL OUTER JOIN 예제 풀이 (0) 2020.04.30